Did you notice any page indexing errors in Google Search Console?
If you’ve spotted them, don’t stress! These errors can hurt your search rankings and make your site harder for users to find. But don’t worry—fixing them isn’t as complicated as it sounds.
I’ll help you identify some important page indexing errors in Google Search Console and show you how to fix them. Stay with me, and we’ll walk through everything step by step!
Important Page Indexing Errors in Google Search Console
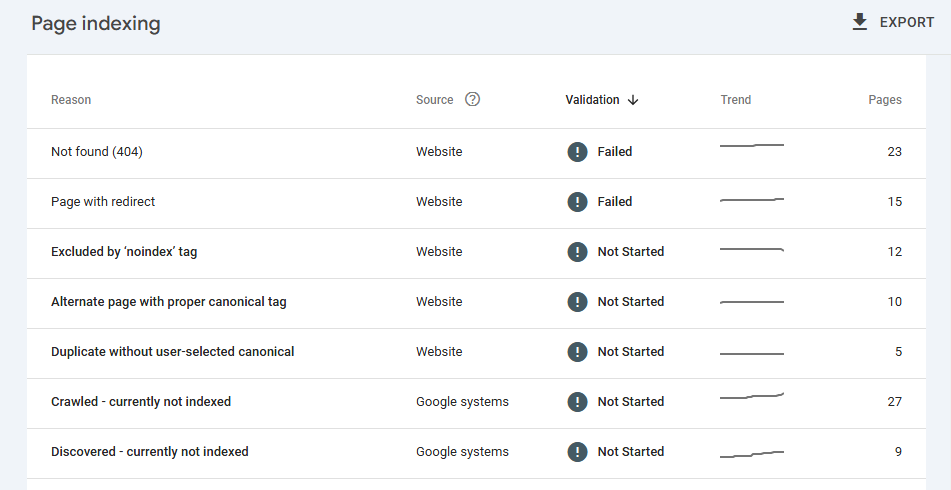
Here are some of the common page indexing errors you might come across in Google Search Console:
- Not found (404)
- Page with redirect
- Excluded by ‘noindex’ tag
- Alternate page with proper canonical tag
- Duplicate without user-selected canonical
- Crawled – currently not indexed
- Discovered – currently not indexed
- Soft 404
- Server error (5xx)
- Blocked due to access forbidden (403)
- Duplicate, Google chose different canonical than user
- Blocked due to other 4xx issue
- Indexed, though blocked by robots.txt
- Page indexed without content
I will explain the reason behind each error and the solution to fix them for you.
Not found (404)
A 404 error pops up when someone tries to visit a page on your site that doesn’t exist anymore. This usually happens when a page is removed, the URL is incorrect, or broken links are pointing to a page that no longer exists.
If you see a Not Found (404) error in the Google Search Console, it needs to be fixed. Leaving it unresolved will negatively affect your website’s SEO performance. A 404 error can increase your bounce rate, prevent search bots from crawling your site, drop traffic, and provide a bad user experience.
How to fix Not Found (404)?
Fixing a Not Found (404) error is simple if you follow these steps:
- Redirect the removed page’s URL to a new one using 301 (permanent) or 302 (temporary) redirects.
- Identify and update any broken internal or external links pointing to the removed page.
- Contact the site owners of backlinks to remove or update the links to the new page.
- Create a custom 404 page to notify visitors of the error, and guide them to a similar relevant page on your site.
Page with Redirect
A Page with Redirect error means the URL you’re trying to index points to another URL instead of directly opening the page. This usually happens when a page has been redirected to a different one using a 301 (permanent) or 302 (temporary) redirect. It could also occur if there are multiple redirect chains or loops.
Redirect Chains: This occur when one URL redirects to another, and that one redirects to yet another, creating a sequence of multiple redirects.
This creates a “chain,” and search engines have to follow multiple steps before reaching the final destination, which can waste the crawl budget and slow down indexing.
Redirect Loops: This happens when a URL keeps redirecting in a circle.
This causes an endless loop, confusing both users and search engine bots. The page never loads, leading to errors.
If this error appears in Google Search Console, it indicates that the redirected page cannot be indexed. Leaving it unresolved can impact your site’s indexing and SEO performance.
How to Fix Page with Redirect?
Here’s how you can fix the Page with Redirect error:
- Streamline redirects: Make sure each redirect goes directly to the final URL. Avoid chaining one redirect to another, as it slows down indexing.
- Prevent redirect loops: Check your redirects carefully and make sure they don’t point back to the same URL or create an endless cycle. Each redirect should lead to a clear, crawlable URL.
- Use permanent redirects: Replace temporary (302) redirects with permanent (301) redirects whenever possible. They’re more reliable for Google bots and better for SEO.
- Set a canonical URL: If a redirected page has multiple versions, define a canonical URL to let Googlebot know which one to prioritize.
Excluded by ‘noindex’ Tag
If there’s a page on your website that you don’t want to show in search results, you can use the noindex tag. But sometimes, this tag is added unintentionally. As a result, your page will be excluded from appearing in search results.
The good news is, that removing the noindex tag makes the page eligible to show up in search results again. You can easily manage this through WordPress plugins or your website’s CMS.
Duplicate Without User-Selected Canonical
This issue happens when you have two identical pages or similar content on your website. Googlebot gets confused about which page to index and rank in search results.
What to Do to Avoid Duplicate Without User-Selected Canonical?
- Add a canonical tag on the duplicate page to point to the preferred version.
- Review your content and ensure there’s no duplication. Write fresh, unique content to stand out.
- Use a 301 redirect to send users and bots from the duplicate page to the preferred one. This also helps preserve link equity.
By following these steps, you ensure Google indexes the right page and avoids any confusion.
Alternate Page with Proper Canonical Tag
When you see Alternate page with proper canonical tag in Google Search Console, it means you’ve set a canonical tag for the preferred version of your page. This helps Google avoid indexing duplicate pages and focus on the main one.
For example, let’s say you have two pages:
- https://example.com/shoes
- https://example.com/shoes?color=red
By setting the canonical tag on the second page to point to the first one, you’re telling Google that https://example.com/shoes is the main page to index.
No further action is needed. Google identifies the canonical page as the main version and excludes duplicate pages from indexing.
Crawled – Currently Not Indexed
Crawled – Currently Not Indexed in Google Search Console isn’t an error; it’s a status. It means Google crawled your page but hasn’t indexed it to the search results yet. This happens due to:
- The page is newly created and undergoing validation.
- Content not meeting quality standards.
- The presence of a noindex tag.
- Crawl budget limitations.
How to Fix Crawled – Currently Not Indexed?
- If it’s a new page, give Google some time to process and decide on indexing.
- Ensure the page has valuable, informative, and unique content that benefits your visitors.
- Remove or modify the noindex tag if you want the page to appear in search results.
- Pass link equity by linking to the page from other relevant and authoritative pages on your site.
- Review your site’s structure and remove unnecessary or low-value pages to help Google prioritize crawling essential pages.
Discovered – Currently Not Indexed
Discovered – Currently Not Indexed in Google Search Console means Google has identified your page but hasn’t processed it for indexing yet. Like the Crawled – Currently Not Indexed status, this often stems from technical issues or content quality concerns.
How to Fix Discovered – Currently Not Indexed?
- Inspect your robots.txt file and ensure there are no blocked pages or broken links.
- Improve both mobile and desktop loading speeds to ensure smooth access for users and search engines.
- Refresh your content with useful, original information and avoid any form of duplication or plagiarism.
By fixing these issues, you can help Google crawl and index your pages more effectively.
Soft 404
This error occurs when a page displays a “not found” message but incorrectly sends a 200 status code. As a result, search engines might interpret the page as active, even though users encounter an error or blank screen, which can impact your SEO.
How to fix Soft 404:
- Make sure your page returns a 404 or 410 status code when the content is genuinely unavailable.
- If the page is still useful, update its content to make it informative and relevant to users.
- Avoid displaying a “not found” message without setting the right HTTP status code.
Server Error (5xx)
Server errors, such as 500, 502, 503, and 504, indicate different issues on the server side. These errors prevent the page from loading as expected, making it inaccessible to users and search engines. These errors usually happen because of server overload, misconfiguration, or temporary downtime.
To resolve a Server Error (5xx) in Google Search Console, follow these steps:
- Check server logs for specific errors and resolve them.
- Ensure your server is properly configured and has enough resources to handle traffic.
- Fix temporary issues like server overload or downtime.
- After fixing the issue, test the page to ensure Googlebot can crawl it successfully.
Blocked Due to Access Forbidden (403)
A 403 error happens when Googlebot is blocked from accessing your page due to restricted permissions. This could be because of settings on your server or security plugins that prevent search engines from crawling certain pages. Here’s how you can solve the issue:
- Check your server or site’s permissions to ensure Googlebot is allowed to crawl the page.
- Review your security plugins or firewalls and ensure they’re not blocking Googlebot or other search engines.
- Verify that the correct robots.txt rules are in place and that they aren’t restricting crawlers from accessing important content.
- If the page needs to be accessible, update the access permissions to allow Googlebot to crawl the page.
Duplicate, Google Chose Different Canonical Than User
This issue occurs when Google selects a different canonical page than the one you’ve set. This can happen if Googlebot identifies what it believes to be a more authoritative version of your page, or if your canonical tag is not set correctly.
To fix the issue:
- Double-check that the canonical tag is pointing to the right URL.
- Make sure the canonical tag is implemented correctly on the duplicate page.
- Review your content and avoid any elements that may confuse search engines about which page is the primary version.
- Use Google Search Console’s URL inspection tool to verify if Google is correctly recognizing the canonical tag.
- Improve the quality and relevance of the content on the canonical page to ensure Google favors it.
Blocked Due to Other 4xx Issue
Errors in the 4xx range typically point to issues with the client’s request. If you come across “Blocked due to other 4xx issues” in Google Search Console, it means Google couldn’t access your page. This could be due to missing files, incorrect URLs, or server issues.
How to fix it:
- Start by reviewing the exact 4xx error (e.g., 404, 401, 403) shown in Google Search Console.
- If it’s a 404 error, ensure the page URL exists, and check for broken links leading to it.
- For 401 errors (unauthorized), make sure your server’s authentication settings are not preventing Googlebot from accessing the page.
- Clear any caching or CDN issues that might be blocking Googlebot.
- Also, check your robots.txt file to make sure Google isn’t being blocked.
Indexed, Though Blocked by robots.txt
When a page gets indexed but is blocked by the robots.txt file, it causes a mismatch. Google has detected the page, but your robots.txt file is blocking it from being crawled or included in search results
This happens when there is an unintended rule in your robots.txt file restricting the page. Google may have indexed the page earlier, but the blocking directive was added later.
How to fix it:
- Check your robots.txt file and remove any blocking rules for that page.
- If you wish to prevent indexing, consider using the “noindex” tag instead of blocking via robots.txt.
- After updating, request reindexing in Google Search Console to resolve the issue.
By doing this, you ensure that Google can correctly crawl and index your page without any restrictions.
Page Indexed Without Content
This status means that Google has indexed a page from your website, but it contains little or no content. Ideally, a webpage should have at least 500–1000 words of valuable content to rank well.
In some cases, placeholders or incomplete pages might unintentionally get indexed. Additionally, issues with your robots.txt file could prevent proper crawling, leading to this problem. So you know what to do to fix this status.
To correct this status:
- First, check Google Search Console for pages with minimal content and add valuable, useful information to them.
- Review the robots.txt file for errors that might block Google from crawling the page. Fix any issues you find.
- If the page isn’t necessary, consider removing it or using a “noindex” tag to prevent it from showing up in search results.
These are the common page indexing errors in Google Search Console that require attention and timely fixes.
Validating Page Indexing Fixes In Google Search Console
After you’ve made changes to address indexing errors in Google Search Console, it’s crucial to validate them. This step ensures that your fixes are effective and your pages are now optimized for indexing.
How to validate page indexing error fixes:
- Utilize the ‘URL Inspection’ feature within Google Search Console to check your page status. Paste the fixed URL to check its updated status.
- After fixing the issue, hit “Request Indexing” to ask Google to re-crawl and update the page.
- Keep an eye on the status updates in the “Coverage” section of the console. Google may take some time to update its index after you’ve made changes.
- Search for your page on Google using “site:yourdomain.com/your-page-url” to confirm it appears in the results.
Validating your Google search console page indexing fixes is as important as addressing the errors. This ensures your efforts lead to improved indexing and search performance.
Need a practical hands-on training on this? Enroll in our online SEO course today.
Did you find this article helpful? Share it with your digital marketing circle!

Vemu Sandeep
